.png?width=1200&height=100&name=%23TRUEDATAOPS.ORG%20Logo%20(1).png)
What is #TrueDataOps?
#TrueDataOps is a philosophy and a specific way of doing things that focuses on value-led development of pipelines (e.g., reduce fraud, improve customer experience, identify opportunities). It takes the truest, battle-hardened principles of DevOps, Agile, Lean, test-driven development, and Total Quality Management and adapts and applies them to the unique discipline of data.
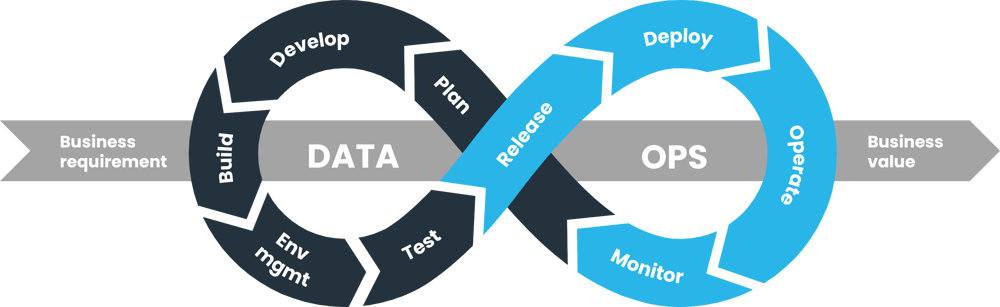
Just like DevOps, companies must embrace this philosophy before they can be successful with any DataOps project. When they do, they’ll see an order-of-magnitude improvement in quality and cycle time for data-driven operations.
The tension between governance and agility is the biggest risk to the achievement of value. It is our view that this tension doesn’t need to exist. Our experience indicates that technology has evolved to the point where governance and agility can be combined to deliver sustainable development through #TrueDataOps.
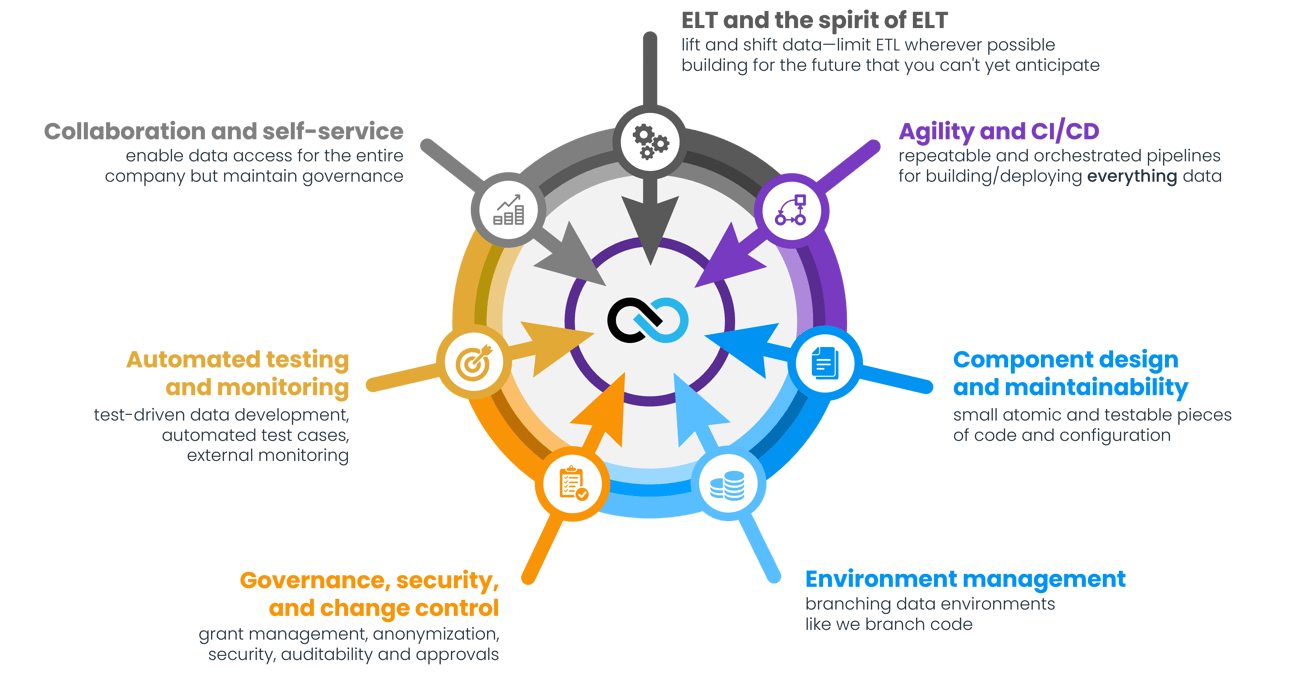
The 7 Pillars of #TrueDataOps
Join the #TrueDataOps movement

Rethink the way you work with data. Join the #TrueDataOps movement and get regular access to DataOps content. Sign up now and get started with the DataOps for Dummies ebook.